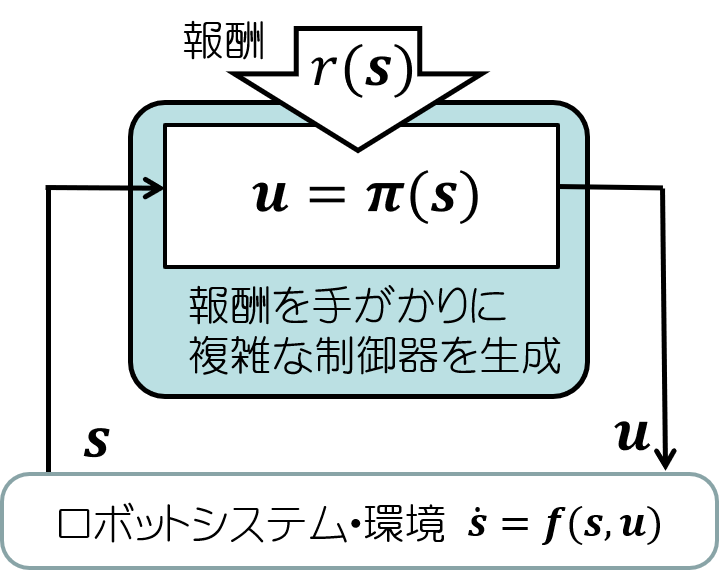
Research activities
Current researches:
Past researches:
Feature Selection and Demonstration-Based Navigation for Environment Recognition
in Unstructured Environments
To enable mobile robots to be deployed across a wide range of real-world
scenarios, it is essential that they operate robustly not only in well-structured
environments such as factories, but also in less organized settings, such
as small- and medium-scale farms. In such unstructured environments, predefined
environment recognition methods?including fixed feature sets and parameters?may
fail to deliver sufficient performance, due to the variability and unpredictability
of the surroundings. To address this issue, we proposed a method that assumes
the user will "demonstrate" a desired navigation path by manually
driving or guiding the robot through the target environment using a controller.
Based on this demonstration, the robot automatically selects and adjusts
the appropriate features and parameters for recognizing the environment.
The key idea is to treat the user-provided path as an indirect supervisory
signal, under the assumption that features spatially close to the demonstrated
path are likely to contain useful information for navigation. We confirmed
that this assumption allowed effective parameter adaptation, resulting
in improved robustness in environment perception. Building on this adaptive
recognition framework, we developed a navigation method that enables the
robot to follow the demonstrated path with high robustness and low computational
cost, even in challenging, poorly structured environments.
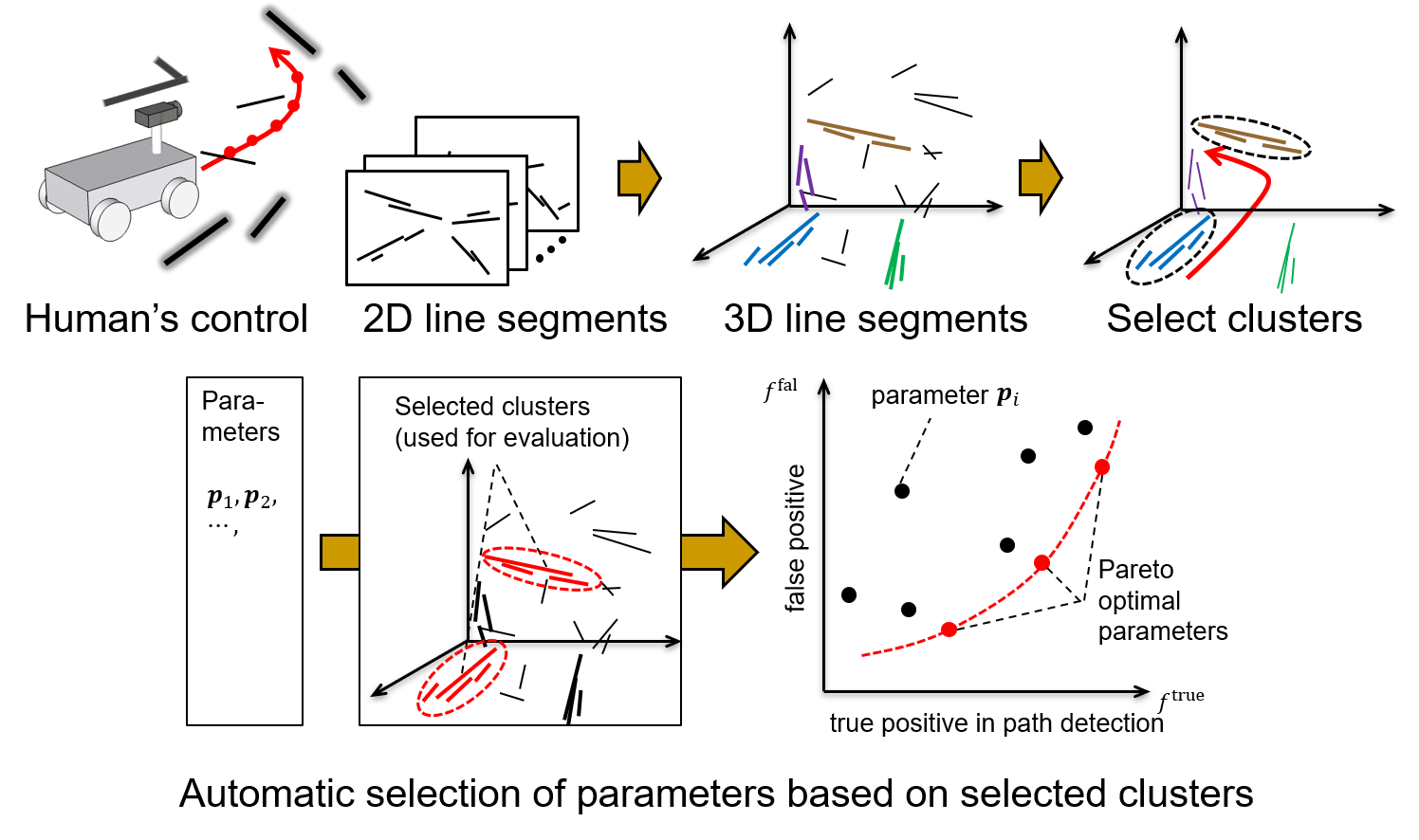 |
 |
| Overview of 3D Line Segment Detection Using Camera Information and Automatic Parameter Adjustment Based on User-Provided Path Demonstration |
An example of ambiguous line segment detection through automatic adjustment of image resolution parameters; an example showing the relationship between the user-demonstrated path (green) and relevant line segments (blue) |
Reference:
- W. Xiang, Y. Kobayashi and S. Azuma, Self-Supervised Learning Approach
under Controller’s Instruction for 3D Line Segment-Based Recognition of
Semi-Unstructured Environment, Proc. of IEEE/SICE International
Symposium on System Integration, 2023 (accepted)
- S. Tanaka, W. Xiang and Y. Kobayashi, Domain Knowledge-Based Automatic
Parameter Selection for 2D/3D Line Segment Detection in Semi-Unstructured
Environment, Proc. of IEEE/SICE International Symposium on System Integration,
pp. 1003-1008, 2022.
- S. Tanaka and Y. Kobayashi, An unsupervised learning approach toward automatic
selection of recognition parameters for mobile robot navigation in less
structured environments, Proc. of IEEE/SICE International Symposium on
System Integration, pp. 6-11, 2021.
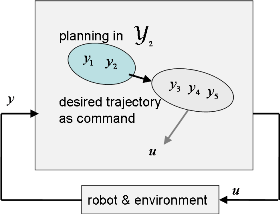
Motion Learning Based on Variable Transformation Estimation Guided by
Controllability
This study proposed a novel method for robot motion generation based on
the principle of discovering spaces that are easy to control. We focused
on a wheeled mobile robot with nonholonomic constraints as a case study
and addressed its nonlinear dynamics using a time-axis state control framework.
In this framework, sensor-observed variables?whose correspondence to internal
system states was unknown?were transformed into variables that are easier
to control. This transformation enabled stable regulation to the target
position (the origin) through simple linear control methods. To demonstrate
the effectiveness of the approach, we applied it to a differential-drive
robot equipped with an RGB camera. The robot successfully performed parking
control based solely on visual observations of landmarks, even when the
visual characteristics of those landmarks were unknown. These results suggest
that learning a mapping to controllable variables can serve as a unified
strategy for nonlinear control and motion generation in robots, particularly
when direct state observation is difficult or unavailable.
Reference:
- K. Nakahara and Y. Kobayashi, Automatic Generation of Feedback Stabilizable
State Space for Non-holonomic Mobile Robots, Proc. of International Conference
on Image Processing and Robotics, 2022.
Learning of object manipulation using tactile information
Visual information, such as depth sensors and stereo cameras, is the main
sensor information for robot manipulation of objects. However, for flexible,
transparent, and translucent objects, it is difficult to grasp the position,
posture, and shape of the object by visual information alone. To solve
this problem, we propose an approach to estimate the position, posture,
and shape of an object based on contact information with the object using
tactile sensors attached to the robot's fingers. The object position and
posture are represented by a probability distribution, and the distribution
is estimated by relying on the tactile sensor information. We will develop
a method for manipulating objects that cannot be accurately identified
visually, including the acquisition of "probing motions" that
are effective for identifying the position and posture of objects.
 |
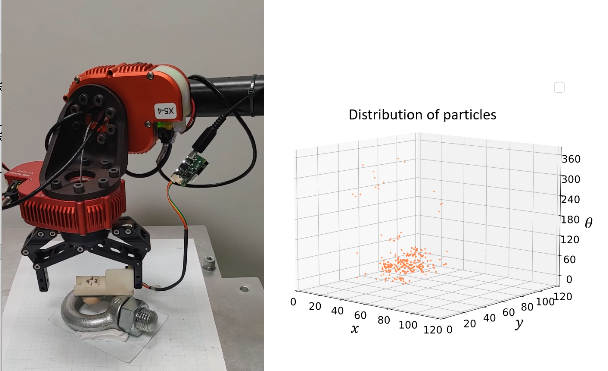 |
|
Example of robot manipulator equipped with tactile sensor
|
Estimation of object pose using partifle filter
|
Reference:
- D. Kato, Y. Kobayashi, N. Miyazawa, K. Hara and D. Usui, Efficient Sample
Collection to Construct Observation Models for Contact-Based Object Pose
Estimation, Proc. of IEEE/SICE International Symposium on System Integration,
2024 (accepted).
- H. Yagi, Y. Kobayashi, D. Kato, N. Miyazawa, K. Hara and D. Usui, Object
Pose Estimation Using Soft Tactile Sensor Based on Manifold Particle Filter
with Continuous Observation, Proc. of IEEE/SICE International Symposium
on System Integration, 2023.
- D. Kato, H. Yagi, Y. Kobayashi, N. Miyazawa, K. Hara and D. Usui, Contact
motion selection for flexible object opening position estimation by tactile
information, Proc. of ISCIE International Symposium on Stochastic Systems
Theory and Its Applications, Nara, Japan, 2022.
- H. Yagi, Y. Kobayashi, D. Kato, N. Miyazawa, K. Hara and D. Usui, Object
Pose Estimation Using Soft Tactile Sensor Based on Manifold Particle
Filter with Continuous Observation, Proc. of IEEE/SICE International
Symposium on System Integration, 2023 (accepted)
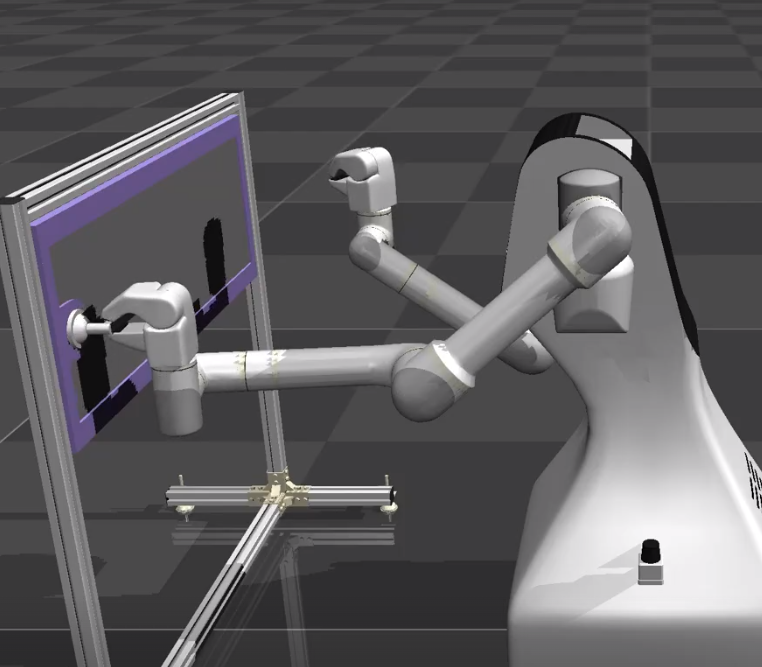
Efficient teaching of robot manipulation under constraint with environment
In production, it is necessary for people to teach the robot's movements.
The most common method of teaching the robot's trajectory is to use a teaching
pendant, but for tasks that involve contact and constraint with the environment
(such as the door-opening motion shown on the left in the figure below),
it takes a lot of effort and time to teach the robot the appropriate motion.
We aim to improve the efficiency of this process by allowing the robot
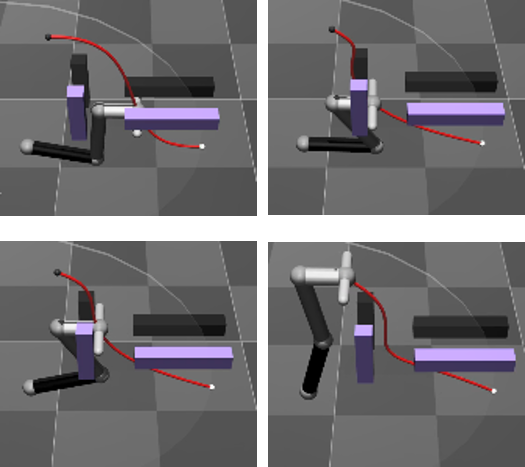
to perform trial and error using contact information. In the right side
of the figure below, the robot starts trial-and-error from a roughly given
path, and when it comes into contact with the environment, it uses the
contact force information to modify the path sequentially. In addition,
we have devised a method to adjust the meta-parameters of such path generation.
 |
 |
|
Example of contrained task by mobile manipulator
|
Succesive modification of path based on contact information by a manipulator
|
Reference:
- 荒井康太,石村芳暉,小林祐一,伊部公紀,マニピュレータへの作業教示時間短縮のための力覚情報を用いた経路生成およびそのメタパラメータの自動調整,第33回自律分散システム・シンポジウム,1A1-1,2021(オンライン開催)
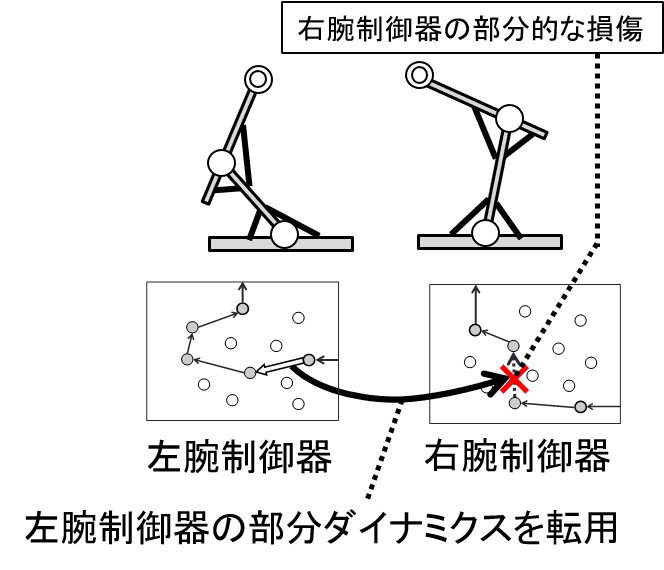
Develpment of human motor learning model that can explain reuse of partial
physical relationship
Human adaptability includes the ability to adaptively recover function
by reusing previously acquired neural circuits when partial dysfunction
occurs in the body or brain. There is a need to understand this adaptive
process. The purpose of this study is to develop a motor learning model
that can reuse partially acquired physical relationships in the controller
by introducing a mechanism called "mapping transformation estimation"
into the motor learning model that estimates dependencies between different
senses. As a specific task, we set up motor learning for both left and
right arms, and have the robot acquire controllers for the left and right
arms separately. By discovering the symmetry of the left and right arms
through the mechanism of "mapping transformation estimation,"
the partial dynamics of the right arm can be used for motion generation
when a part of the control circuit of the left arm malfunctions.
 |
 |
|
Estimation of partial physical relationship in motor learning
|
Reuse of physical relationship between two controllers for left and right
arms
|
Reference:
- 小林祐一,運動学習における部分ダイナミクスの変換推定のための分散型計算法の検討,第33回自律分散システム・シンポジウム,2A1-2,2021(オンライン開催)
- S. Nakamura and Y. Kobayashi, A Grid-Based Estimation of Transformation of Partial Dynamics using Genetic Algorithm for Motor Learning, Proc. of The 32nd 2021 International Symposium on Micro-NanoMechatronics and Human Science, MP2-2-3, 2021.
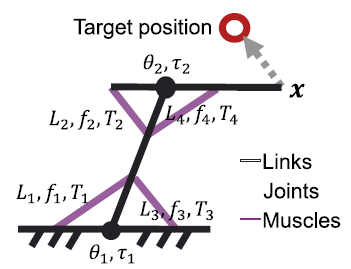
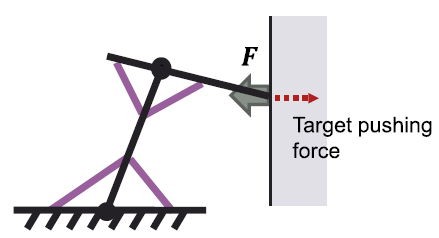
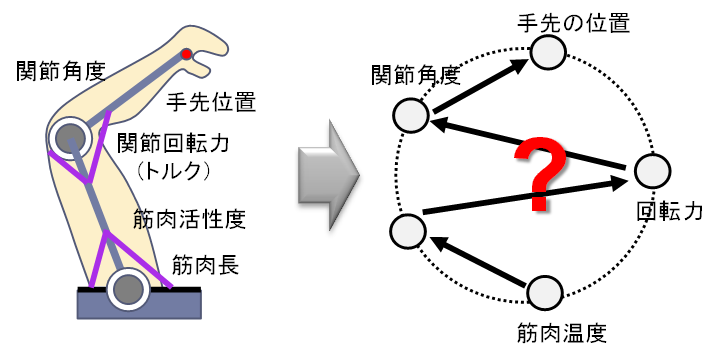
Automatic Generation of Control Laws for Musculoskeletal Arm Systems Based
on the Estimation of Dependencies among Different Sensors
Conventional motor learning methods are based on fixing state variables
and control inputs, and identifying their input-output relationships in
a black-box manner. In contrast, in this research, we consider a system
that can perform redundant and multimodal sensing, and consider a method
for motor control that includes the process of identifying dependencies
between different sensors and estimating "which sensor information
can be used to achieve the desired control. As a concrete example, we consider
a musculoskeletal arm-arm system with artificial muscles. We estimate the
dependency between various sensor information using mutual information,
trace the dependency, and check the controllability of the other variable
by controlling one of them. A control law is automatically generated by
accumulating this process. It was confirmed that a common methodology can
be used to achieve different objectives, such as tracking control and force
control, and that a motor learning method that can adapt to partial failures
and changes can be constructed.
Reference:
- Y. Kobayashi, K. Harada and K. Takagi, Automatic Controller Generation
Based on Dependency Network of Multi-modal Sensor Variables for Musculoskeletal
Robotic Arm, Robotics and Autonomous Systems, Vol. 118, pp. 55-65, 2019.
- K. Harada and Y. Kobayashi, Estimation of structure and physical relations
among multi-modal sensor variables for musculoskeletal robotic arm, Proc.
of IEEE International Conference on Multisensor Fusion and Integration
for Intelligent Systems, 2017.
- 原田健太郎,小林 祐一,センサ変数ネットワークの構造同定にもとづいた筋骨格ロボットの制御則の自動生成,第18回計測自動制御学会システムインテグレーション部門講演会 (2017年12月)
Navigation of mobile robots considering human interaction in high-density
crowded environments
Navigation of mobile robots in crowded environments such as train stations
and stadiums requires consideration of interaction with people, consideration
of the flow of people, and avoidance of not only collision avoidance but
also psychological pressure on people. In this study, we developed, implemented,
and verified a navigation method for driving in a crowded environment without
interfering with the flow of people based on the information collected
in the simulation. In this study, we developed, implemented, and verified
a navigation method for driving in a crowded environment without interfering
with the flow of people, based on the information collected in the simulation.
A common problem in research on navigation in such a dense crowded environment
is that it has not been compared in a common environment. In this study,
we propose a test method to compare and evaluate the navigation performance
of robots under the same conditions while controlling the density of human
flow, and show the video of the experiment.(Example of navigation settings)
 |
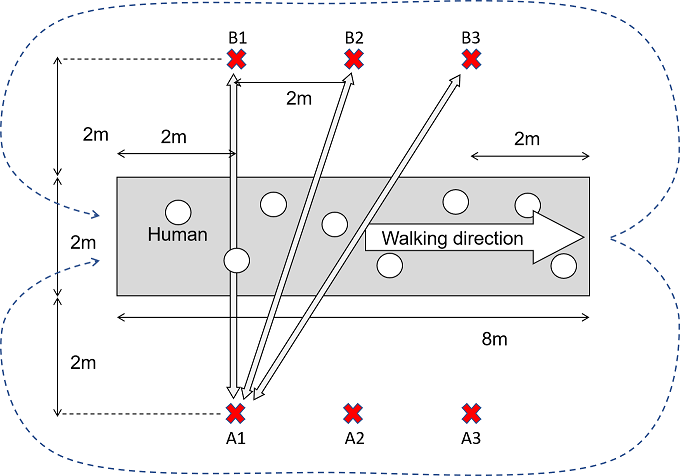 |
| 高密度雑踏環境下での移動ロボットのナビゲーション |
再現可能な高密度人流環境でのナビゲーション実験方法 |
Reference:
- Y. Kobayashi, T. Sugimoto, K. Tanaka, Y. Shimomura, F. G. Arjonilla, C.
H. Kim, H. Yabushita, T. Toda, Robot navigation based on predicting of
human interaction and its reproducible evaluation in a densely crowded
environment, International Journal of Social Robitcs, in press, 2021.
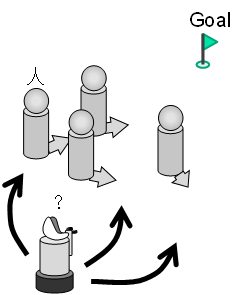
Recognition of task execution status using natural language for robots
that collaborate with humans
In order to realize a robot that can collaborate with humans in the same
environment, it must be able to cope with anomalies (failures) and task
variations. In particular, it is desirable for the robot to be able to
communicate with its collaborators in language, to recognize failures more
accurately, and to reflect their requests in its behavior. In this study,
we develop a robot system that can respond to a person's request to correct
its behavior and point out abnormalities (failures) in its work using natural
language. Using motion data collected from real-world data and natural
language data in which humans describe the situation, we develop a method
to identify the execution state and motion status of a task and modify
the motion. By doing so, we aim to realize robot intelligence that is more
compatible with humans in a data-driven manner that reduces the design
burden on designers (experts).
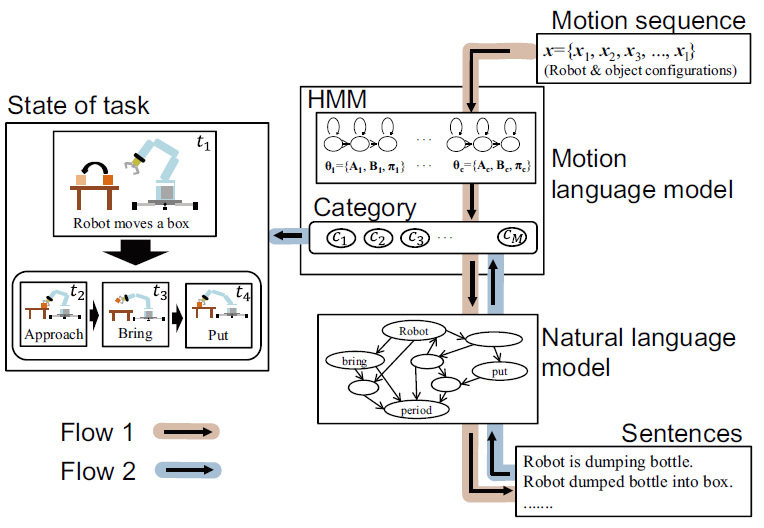 |
 |
| Recognition of task states based on sentence and motion information |
Example of task execution scenario by robot manipulator with a gripper |
Reference:
- 阿部卓未,小林祐一,高野渉,Dirk Wollherr,Volker Gabler,人と協働するロボットのための類似性を反映した自然言語による状態識別,第30回自律分散システム・シンポジウム
- Y. Kobayashi, T. Matsumoto, W. Takano, D. Wollherr and V. Gabler, Motion
recognition by natural language including success and failure of tasks
for co-working robot with human, Proc. of IEEE International Conference
on Advanced Intelligent Mechatronics, pp. 10-15, 2017.
Environmental recognition reflecting the vehicle's driving experience in
rough terrain environments
In this study, we propose a flexible environment recognition method based
on feature extraction from image information based on information obtained
by the robot's own motion. For the navigation problem of an autonomous
mobile robot equipped with a camera and a laser range finder (LRF), we
propose a method for recognizing obstacles on the road, which are difficult
to distinguish by 3D shape recognition based on distance measurement, based
on the correlation between image features and driving experience. We propose
a method for recognizing obstacles on the road, which are difficult to
identify by distance measurement-based 3D shape recognition, based on the
extraction of correlations between image features and running experience.
This method enables us to realize a robot that can move intelligently while
identifying and judging whether it is easy to run and how to run.
 |

 |
| Uneven rough terrain in outdoor environment |
Example of mobile robot and visual information processing |
Reference:
- M. A. Bekhti and Y. Kobayashi, Regressed Terrain Traversability Cost for Autonomous Navigation Based on
Image Textures, Applied Science, Vol. 10, No. 4, 1195, 2020.
- M. A. Bekhti and Y. Kobayashi, Prediction of Vibrations as a Measure of
Terrain Traversability in Outdoor Structured and Natural Environments,
Lecture Notes in Computer Science (LNCS) 9431, 7th Pacific-Rim Symposium,
PSIVT 2015 Auckland, New Zealand, November 25-27, 2015, Revised Selected
Papers, Thomas Braunl, Brendan McCane, Mariano Rivera, Xinguo Yu (Eds.)
2016. (DOI: 10.1007/978-3-319-29451-3, ISBN: 978-3-319-29450-6)
- Mohammed Abdessamad Bekhti, Soudai Tanaka, Yuichi Kobayashi, Toru Kaneko,Image
Feature-based Traversability Analysis for Mobile Robot Navigation in Outdoor
Environment,日本機械学会ロボティクス・メカトロニクス講演会,1P1-C06, May. 2014.
Autonomous navigation of unmanned vehicles in unknown rough terrain environments
We propose a method of navigation in an unknown (unmapped) uneven terrain environment by making intelligent decisions based only on the information of the target point and nearby observations. the system determines whether a road is a runway or not based on the information from the laser rangefinder (LRF), and generates a route based on the results of the determination. When the vehicle reaches a fork, it decides which path to take based on its past experience of optimal control, and proposes a smarter path selection method than simply choosing the one that is closer to the target point. The proposed control method is verified using a simulator and an actual vehicle, which are constructed based on an actual rough terrain environment.
 |
 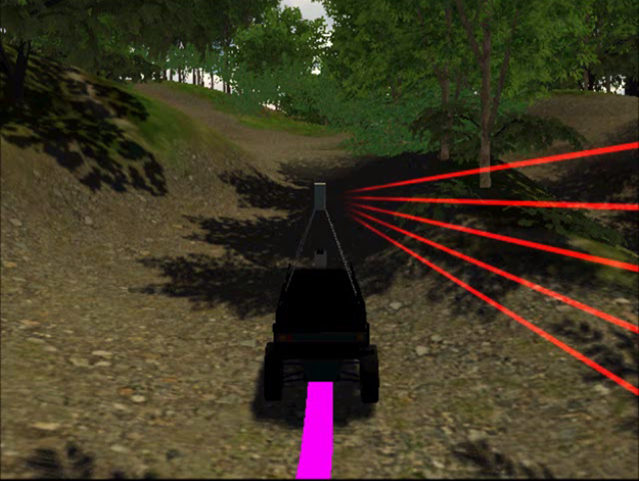 |
| UGV navigation in rough terrain outdoor environment |
Recognition of environment and navigation in simulation |
Reference:
- 須永賢治,小林祐一,金子透,平松裕二,藤井北斗,神谷剛志,屋外不整地環境における無人車両のための走路判別,精密工学会誌,Vol. 79, No. 11, pp. 1117-1123, 2013.
- Y. Kobayashi, M. Kondo, Y. Hiramatsu, H. Fujii and T. Kamiya, Action Decision of Mobile Robot Unmanned Ground Vehicle Based on Offline
Simulation for Navigation in Uneven Terrain Environment, Journal of Robotics and Mechatronics, Vol. 30, No. 4, pp. 671-682, 2018.
State recognition based on image feature dependency and motion generation
視覚入力の中から,「関係のあるもの」と「関係のないもの」を識別する過程を自律的に獲得できるロボットの学習法を提案する.ロボット身体や背景・物体に関する視覚的特徴や空間中の位置関係などに関する事前知識を用いずに,特徴間の位置変化や遮蔽による消失などの情報だけをもとに離散的な状態識別を行う.抽出を行った身体及び物体の特徴クラスタから,関節角度に対する条件付き確率を用いて位置予測を行うことで,リーチングや回避などの行動生成につなげられる.
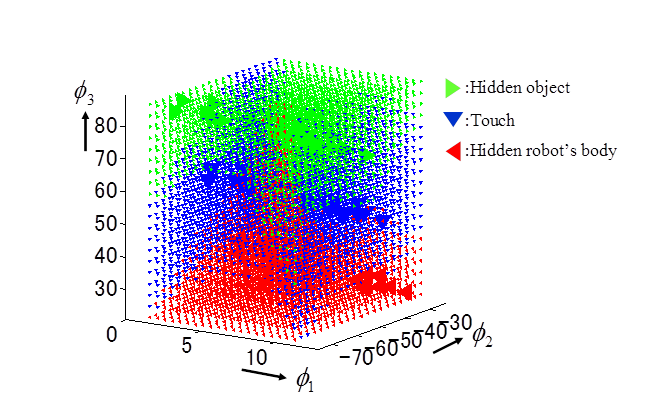 |
  |
| 確率的な依存関係を用いた状態識別の例 |
視覚特徴間の依存関係を表すネットワークの生成例 |
- Takayuki Somei, Yuichi Kobayashi, Akinobu Shimizu and Toru Kaneko, "
Clustering of Image Features Based on Contact and Occlusion among Robot
Body and Objects", Proceedings of the 2013 IEEE Workshop on Robot
Vision (WoRV2013), 2013.
- 染井貴之,小林祐一,清水昭伸,金子透,"重点サンプリングによる探索を利用した空間認知のための視覚特徴クラスタ統計学習,” 第30回日本ロボット学会学術講演会予稿集,AC3N1-4, 2012.
Teaching of holding-up motion by humanoid robot using force sensor information
This research proposes a manipulation acquisition framework based on off-line
trials with failure/success. Two feature spaces are constructed using nonlinear
mapping, feature space of force sensor information and feature space of
configuration space. Thay are used to modify holding-up motion online.
First a robot tries to hold up an object and verifies its force sensor
information. The robot predicts whether tha task can be achieved using
the sensor information. When it is predicted that the robot will fail to
hold up, it modifies the configuration using the feature space information.
The proposed framework was evaluated by simulations with a humanoid robot.
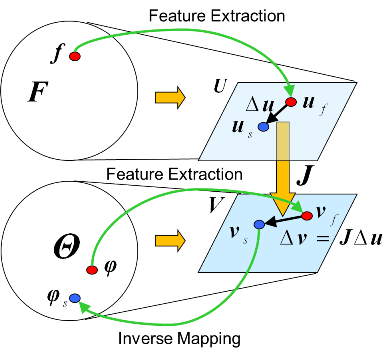 Idea of modification of holding-up configuration Idea of modification of holding-up configuration
using force sensor information |

Evaluation of holding-up motion by simulation
with a humanoid robot |
- Yuichi Kobayashi and Masanobu Tsubota, "Hold-up motion generation
based on feature extraction of force sensor information", JSME Robotics
and mechatronics conference, (to be presented), 2011.
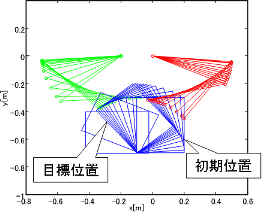
Extraction of modes related to motions of body and objects and planning space shift motion generation
To improve the flexibility of robotic learning, it is important to
realize an ability to generate a hierarchical structure.
This paper proposes a learning framework which can
dynamically change the planning space depending on the structure of
tasks.
Synchronous motion information is utilized to generate
’modes’ and hierarchical structure of the controller is constructed
based on the modes. This enables efficient planning and
control in low-dimensional planning space, though the dimension of
the total state space is in general very high. Three types
of object manipulation tasks are tested as applications, where
an object is found and used as a tool (or as a part of the
body) to extend the ability of the robot. The proposed framework
is expected to be a basic learning model to account for body
schema acquisition including tool affordances.
Idea of motion generation based on separation of path planning of object
and body |
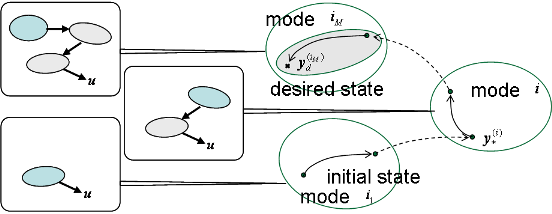
Total scheme of motion generation with multiple mode transitions which
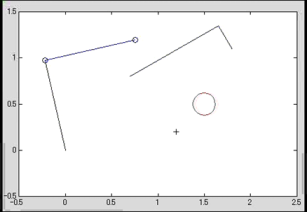
consist of modes with body motion and with body and object motions |
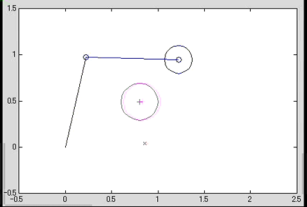 Pushing motion generation considering multiple mode transitions Pushing motion generation considering multiple mode transitions |
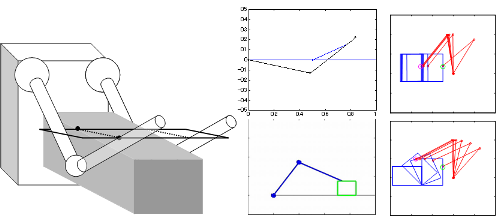
Object manipulation with an L-shaped tool, obtained by the proposed motion
generation framework |
- Yuichi Kobayashi and Shigeyuki Hosoe, Planning-Space Shift Motion Generation:
Variable-space Motion Planning: Toward Flexible Extension of Body Schema,
Journal of Intelligent and Robotic Systems, volume 62, issue 3-4, 2011.
- Yuichi Kobayashi and Shigeyuki Hosoe, ``Planning-Space Shift Learning:
Variable-space Motion Planning toward Flexible Extension of Body Schema,''
Proc. of IEEE/RSJ Int. Conf. on Intelligent Robot and Systems, 373-379,
2009.
Learning of object manipulation considering stick/slip contact mode change
This research proposes the learning of whole arm manipulation with a two-link
manipulator. Our proposal combines a controller obtained by reinforcement
learning (actor-critic) and a learning classifier realized by a Support
Vector Machine (SVM). The classifier learns the boundary between slip and
stick modes in torque space. Using the result of classification, the robot
learns to move the object toward desired position while keeping the desired
contact modes. Control input (torque) is first specified by the actor.
The SVM classifier judges whether torque can maintain the desired slip
or stick mode and, if not, it modifies the torque so that the desired mode
is maintained. It was verified in the simulation that our proposed learning
realized accelerating of the object and decelerating it while keeping the
desired mode, i.e., avoiding undesired slipping of the object.
Examples of object manipulation with contact mode changes:
Holding up, pushing and rotating manipulations |
Learning of object rotation task using SVM and model predictive control |
- Nobuyuki Kawarai and Yuichi Kobayashi, Learning of whole arm manipulation
with constraint of contact mode maintaining, Journal of Robotics and Mechatronics,
Vol. 22, No.4, 542-550, 2010.
- Yuichi Kobayashi, Masashi Shibata, Shigeyuki Hosoe and Yoji Uno, ``Learning
of Object Manipulation with Stick/Slip Mode Switching,'' IEEE/RSJ 2008
Int. Conf. on Intelligent Robot and Systems, 373-379, 2008.
Extraction of body/object information from images for robot motion generation
It is important for robots that act in human-centered environments to build
image processing in a bottom-up manner. This paper proposes a method to
autonomously acquire image feature extraction that is suitable for motion
generation while moving in unknown environment. The proposed method extracts
low level features without specifying image processing for robot body and
obstacles. The position of body is acquired in image by clustering of SIFT
features with motion information and state transition model is generated.
Based on a learning model of adaptive addition of state transition model,
collision relevant features are detected. Features that emerge when the
robot can not move are acquired as collision relevant features. The proposed
framework is evaluated with real images of the manipulator and an obstacle
in obstacle avoidance.

Extraction of visual features relevant to collision and motion generation
using the extracted features |
Extraction of body and object based on random exploration and object manipulation
using the extracted information |
- Taichi Okamoto, Yuichi Kobayashi and Masaki Onishi, Acquisition of Body
and Object Representation Based on Motion Learning and Planning Framework,
Proc. of the 9th Int. Conf. on Intelligent Systems Design and Applications,
737-742, 2009.
- Takahiro Asamizu and Yuichi Kobayashi, Acquisition of image feature on
collision for robot motion generation, Proc. of the 9th Int. Conf. on Intelligent
Systems Design and Applications, 1312-1317, 2009.
Motion Generation by Integration of Multiple Observation Spaces for Robots
with Limited Range of Observation
Sensors of robots that act in unstructured environment sometimes do not
provide complete observation, due to occlusion or limitation of sensing
range. This paper presents a motion generation method for robot with multiple
sensors with limited sensing ranges. The proposed method introduce extension
of the action-observation mapping to outside of the sensing range of a
sensor, based on the diffusion-based learning of Jacobian matrices between
control input and observation variable. Multiple observation spaces can
be integrated by finding correspondence between the virtual observation
spaces. When a target observation variable is given to the robot, it can
generate a motion from an observation space toward the target with another
observation space using the extended observation space. The proposed framework
is verified by two robot tasks, reaching motion toward the floor with a
manipulator and navigation of mobile robot around the wall. In both cases,
observation space by camera with limited view was extended and appropriate
motion trajectories were obtained.
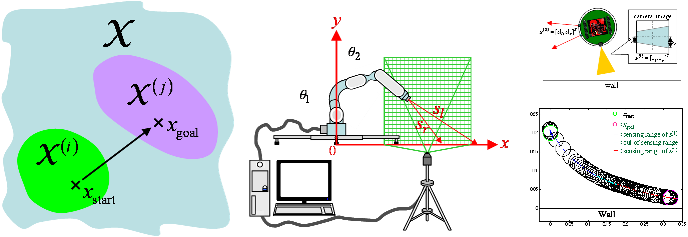
|
Figure(left): Motion generation from sensor(observable) space (i) to sensor
space (j)
Figure(mid): Application (1); Observation of end-effector by camera and measurement of distance to floor with proximity sensor
Figure(right): Application (2); Navigation of mobile robot toward a wall
with camera and proximity sensor |
- Eisuke Kurita, Yuichi Kobayashi, Manabu Gouko, Motion Generation by Integration
of Multiple Observation Spaces for Robots with Limited Range of Observation,
2011 International Conference on Control, Robotics and Cybernetics, 2011
(accepted).
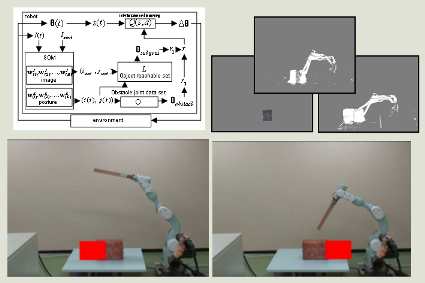
Design of Parallel Tasks of Human-interacting Robot using Optimization
and Optimal Control
Robots that interact with humans in household environments are required
to achieve multiple simultaneous tasks such as carrying objects,
collision avoidance and conversation with human, in real time. This
paper presents a design framework of multiple human-interacting tasks
to meet the requirement by considering stochastic behavior of humans.
The proposed designing method first introduces petri-net for parallel
multiple tasks. The petri-net formulation is converted to Markov
decision processes and processed in optimal control framework. Multiple
task arbitration is resolved by optimization with approximated value
functions. Two tasks of safety confirmation and conversation tasks are
mutually interacting and expressed by petri-net. Tasks that normally
tend to be designed by integrating many if-then rules can be dealt with
in a systematic manner in the proposed framework, that is, in a state
estimation and optimization framework. The proposed arbitration method
was verified by simulations and experiments using RI-MAN, which was
developed to do interactive tasks with humans.
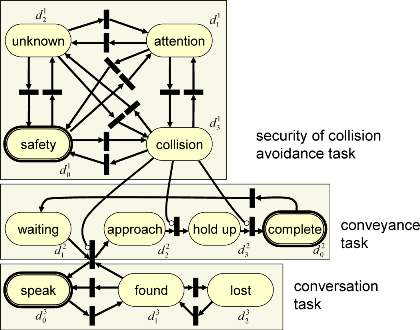 |
 |
| Expression of parallel tasks by petri net |
Experiment with RI-MAN in human-interactive environment |
Publication:
- Yuichi Kobayashi, Masaki Onishi, Shigeyuki Hosoe, Zhiwei Luo, ``Behavior
Design of A Human-interactive Robot through Parallel Tasks Optimization,''
Proc. of the 9th International Symposium on Distributed Autonomous Robotic
Systems (DARS2008), 2008.
Autonomous decentralized control of capturing behavior by multiple mobile
robots
This research discusses the design of decentralized capturing behavior
by multiple mobile robots. The design is based on a gradient descent method
with local information. The task of capturing a target is divided into
two problems, enclosing behavior and grasping behavior. We give analysis
on convergence of the local control policy in enclosing problem. In grasping
behavior, we consider the force-closure condition in decentralized form
for designing a local objective function. The proposed local control policies
were evaluated in simulations, where the flexibility of the system was
verified caused by the decentralized nature of the system.

Enclosing behavior of a circular moving object by 6 robots
|
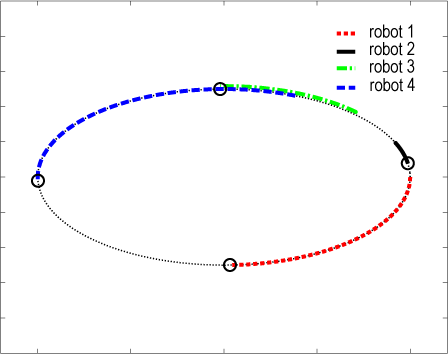
Grasping behavior of an ellipsoidal object by 4 robots
|
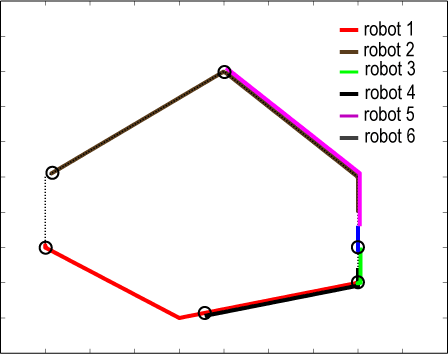
Grasping behavior by 6 robots
|

Experiment with mobile robots
|
- Yuichi Kobayashi, Kyouji Otsubo and Shigeyuki Hosoe, ``Design of Decentralized
Capturing Behavior by Multiple Mobile Robots,'' IEEE 2006 Workshop on Distributed
Intelligent Systems, 13-18, 2006.
- 小林祐一,大坪恭士,細江繁幸,"群移動ロボットによる協調捕獲行動の自律分散制御", 第6回計測自動制御学会制御部門大会資料, Vol.2, pp.463-468, 2006.
- 小林祐一,大坪恭士,細江繁幸,野田幸男,"分散協調捕獲行動のための群移動ロボット制御", 第16回インテリジェント・システム・シンポジウム講演論文集, pp.171-176, 2006.
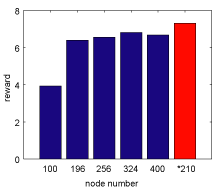
Optimizing Resolution for Feature Extraction in Robotic Motion Learning
This paper presents a feature extraction method for robotic motion learning that optimizes image resolution to the task, thereby minimizing computation time. It utilizes mean-shift algorithms and principal component analysis for feature extraction, reinforcement learning for motion learning, and trial and error for finding the appropriate resolution. When applied to a manipulator pushing an object, the resolution adjustment method reduces the task time from one minute to 21 seconds.
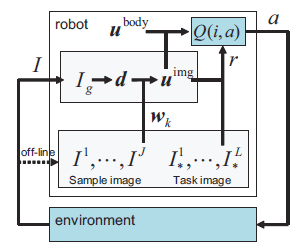
Proposed architecture for feature extraction from image inputs
|

Experimental setup with camera and manipulator for object pushing task
|
 Flow of feature extraction using image information Flow of feature extraction using image information |
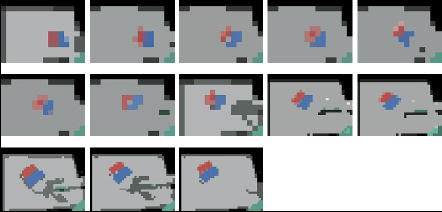
Pocessed images at each time step with different resolutions
|
- Masato Kato, Yuichi Kobayashi and Shigeyuki Hosoe, ``Optimizing Resolution for Feature Extraction in Robotic Motion Learning ,'' IEEE Int. Conf. on Systems, Man & Cybernetics, Hawaii USA, 1086-1091, 2005.
Reinforcement learning for object manipulation using low-dimensional mapping
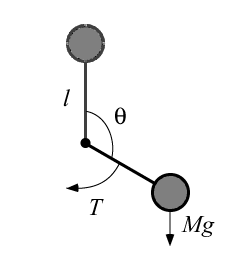
This paper proposes a reinforcement learning method for dynamic control problems with holonomic constraints. The learning method is applicable to problems where the actual motion of the system is restricted to lower-dimensional submanifolds, so long as certain conditions are satisfied. Such dynamic control problems occur in robotic manipulation, which usually includes some holonomic constraints between the object and the robot or the environment. By introducing nonlinear mapping to one-dimensional space and approximating the boundary of a discontinuous reward function, the proposed method results in effective learning. The method is evaluated in a one degree of freedom object rotating task with contact force considerations. The effectiveness of the proposed learning method was verified by comparison to ordinal Q-learning and Dyna without the proposed mapping method.
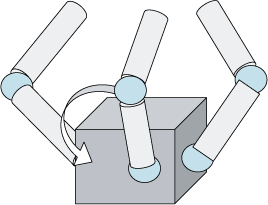
Constrained motion of manipulation by robot hand
|
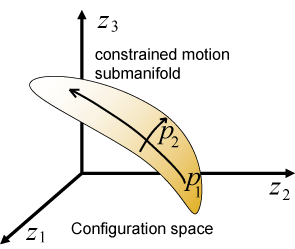
Submanifold generated by constrained motion in configuration space
|
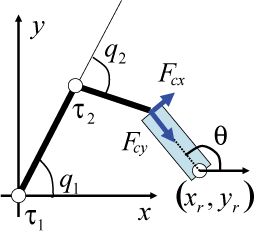
Object rotation task with cosnraint to keep contact between hand and object
|
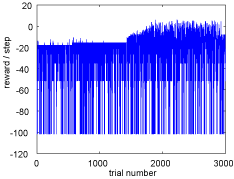
An example of reward profile
|
- Yuichi Kobayashi, Hiroki Fujii and Shigeyuki Hosoe, ``Reinforcement learning for object manipulation using low-dimensional mapping,'' Transactions of the Society of Instrument and Control Engineers, Vol.42, No.7, 2006.
- Yuichi Kobayashi, Hiroki Fujii and Shigeyuki Hosoe, ``Reinforcement Learning for Manipulation Using Constraint between Object and Robot,'' IEEE Int. Conf. on Systems, Man & Cybernetics, Hawaii USA., 871-876, 2005.
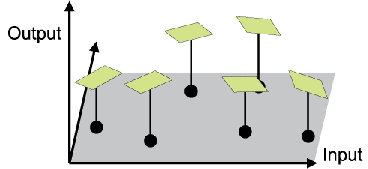
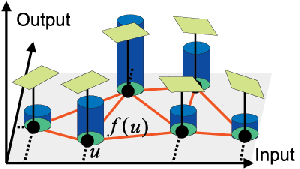
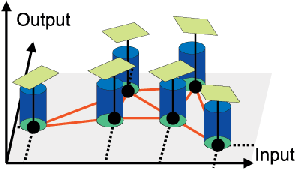
Hyper-cubic function approximation for reinforcement learning based on autonomous-decentralized algorithm
Adaptive resolution of function approximator is known to be important when we apply reinforcement learning to unknown problems. We propose to apply successive division and integration scheme of function approximation to Temporal Difference learning based on local curvature. TD learning in continuous state space is based on non-constant value function approximation, which requires the simplicity of function approximator representation. We define bases and local complexity of function approximator in the similar way to the autonomous decentralized function approximation, but they are much simpler. The simplicity of approximator element bring us much less computation and easier analysis. The proposed function approximator is proved to be effective through function approximation problem and a reinforcement learning common problem, pendulum swing-up task and acrobot stabilizing task.
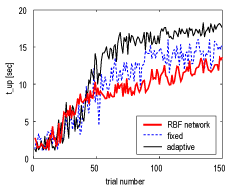
Comparison of learning performance among RBF network, fixed approximation and proposed adaptive resolution approximation
|
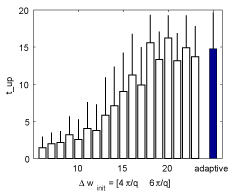
Performance of control obtained by adaptive resolution function approximation
|
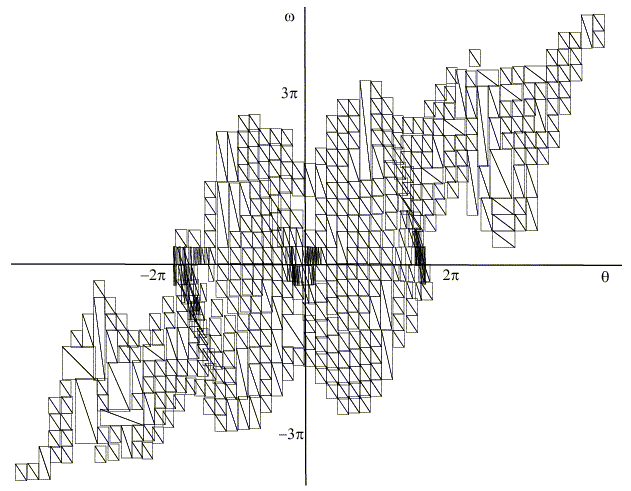
An example of adaptive resolution in pendulum swing-up application |
Publication:
- Yuichi Kobayashi, Hideo Yuasa, Shigeyuki Hosoe, ``Hyper Cubic Function Approximation for Reinforcement Learning Based on Autonomous-Decentralized Algorithm,'' Transactions of the Society of Instrument and Control Engineers, Vol. 40, No. 8, 849-858, 2004 (in Japanese)
- Yuichi KOBAYASHI and Shigeyuki HOSOE, ``Adaptive Resolution Function Approximation for TD-learning: Simple Division and Integration,'' Proc. of SICE Annual Conference 2003, Fukui, Japan, 3023-3028, 2003.
- Yuichi Kobayashi and Shigeyuki HOSOE, ``Hyper-Cubic Discretization in Reinforcement Learning Based on Autonomous Decentralized Approach,'' IEEE Int. Conf. on Systems, Man & Cybernetics, Washington D.C. USA, 3633-3638, 2003.
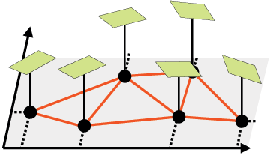
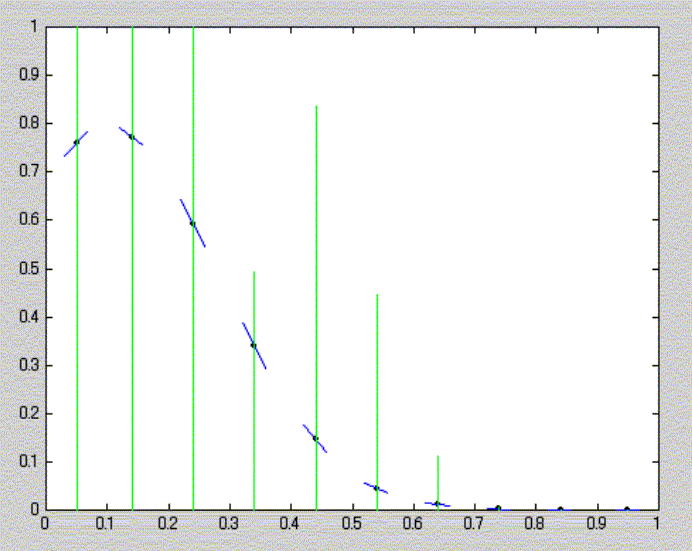
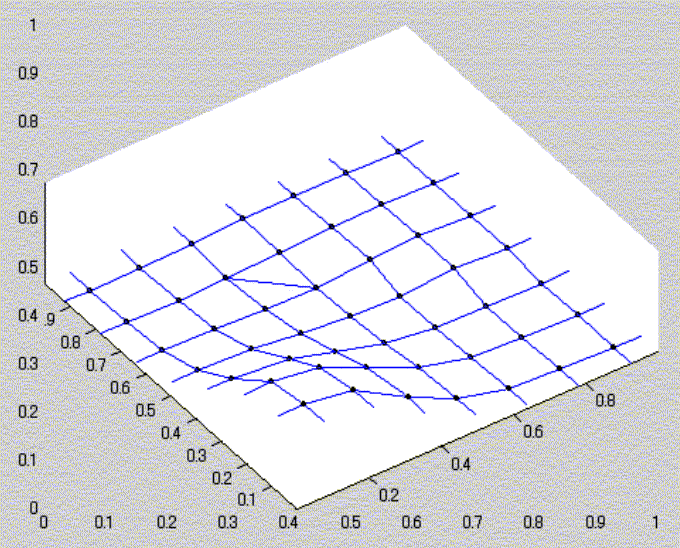
Function approximation for reinforcement learning using autonomous-decentralized algorithm
The adaptability of resolution to the complexity of approximated function has a great influence on the performance of learning in the function approximation for reinforcement learning. We propose applying the reactiondiffusion equation on a graph to function approximation for reinforcement learning.The function approximator expressed by nodes can change its resolution adaptively by distributing them densely in the complex region of the state space with the proposed algorithm. A function is expressed in a plane. The successive least square method is adopted to approximate the function from the data.Each plane corresponds to a node, which is an element of the graph.Each node moves to diffuse the complexity of the approximated function in the neighborhood based on the reaction-diffusion equation.The complexity of the function is defined by the change of gradient. The simulation shows the two points: 1) The proposed algorithm provides the adaptability for function approximation. 2) The function approximation improves the efficiency of the reinforcement learning.
Publication:
- Yuichi Kobayashi, Hideo Yuasa, Tamio Arai, ``Function Approximation for Reinforcement Learning Using Autonomous-Decentralized Algorithm,'' Transactions of the Society of Instrument and Control Engineers, Vol. 38, No. 2, 219-226, 2002 (in Japanese)
- Yuichi KOBAYASHI, Hideo YUASA and Shigeyuki HOSOE, ``Q-learning with Adaptive Resolution Function Approximation based on Graph,'' Proc. of the ICASE/SICE Workshop: Intelligent Control and Systems, Muju, Korea, 79-84, 2002.
- Yuichi Kobayashi, Hideo Yuasa, and Tamio Arai, ``Function Approximation for Reinforcement Learning Based on Reaction-Diffusion Equation on a Graph,'' Proc. of SICE Annual Conference 2002, Osaka, Japan, 916-921, 2002.
Design of quadruped robot soccer behavior considering observational cost
In this paper, we present a real-time decision making method for a quadruped robot whose sensor and locomotion have large errors, considering the observational cost and the optimality. We make a State-Action Map by off-line planning considering the uncertainty of the robot's location with Dynamic Programming (DP). Using this map, the robot can immediately decide optimal action which minimizes the time to reach a target state at any states. The number of observation is also minimized. We compress this map for implementation with Vector Quantization (VQ). The total loss of optimality through compression is minimized by using the differences of the values between the optimal action and the others. In the simulation, the performance of some soccer behaviors were improved in comparison with current methods. The proposed method is implemented on the real robot and the low computation under the restriction of the memory was verified in the experiment.
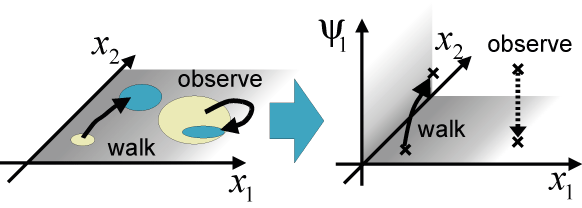
Expression of state transition with uncertainty in state space including uncertainty parameter
|
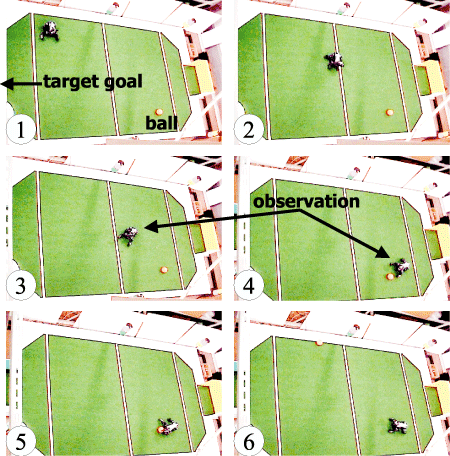
An example of observation strategy with real quadruped robot |
Publication:
- Yuichi Kobayashi, Takeshi Fukase, Ryuichi Ueda, Hideo Yuasa, Tamio Arai, ``Design of Quadruped Robot Soccer Behavior Considering Observational Cost,'' Journal of the Robotics Society of Japan, Vol. 21, No.7, 802-810 (in Japanese), 2003
- Takeshi Fukase, Yuichi Kobayashi, Ryuichi Ueda, Takanobu Kawabe and Tamio Arai, ``Real-time Decision Making under Uncertainty of Self-Localization Results,’’ The 2002 International RoboCup Symposium Pre-Proceedings, 372-379, 2002.
- Takeshi FUKASE, Masahiro YOKOI, Yuichi KOBAYASHI, Hideo YUASA and Tamio ARAI, ``Quadruped Robot Navigation Considering the Observational Cost,'' Andreas Birk, Silvia Coradeschi and Satoshi Tadokoro (Eds.), RoboCup 2001: Robot Soccer World Cup V, Springer, 350-355, 2002.
Back to TOP PAGE